Pojďme tedy začít se samotným programováním. Ovšem nejdříve si musíme vše naplánovat a rozhodnout se, kde začneme. Vzhledem k tomu, že jsme zvolili objektově-orientovanou koncepci, začneme určitě modulem Livescore.pm. Napíšeme konstruktor a potom můžeme klidně postupovat podle bodů, které jsme si vytýčili posledně. Nuže, dejme se do doho.
Konstruktor
Nyní je třeba učinit ješte jedno rozhodnutí. Co bude uchovávat objekt? Určitě bude třeba v nějaké formě uložit stránku, ze které budeme stahovat data. Dnešní zápasy jsou k dispozici na http://www.livescore.com/default.dll?page=home, zápasy v rámci České republiky na http://www.livescore.com/default.dll?page=czechia apod. V první verzi konstruktoru tedy uchováme home, czechia apod., které přijde jako parametr konstruktoru od uživatele. Konstruktor zatím necháme být, protože se ještě může spousta věcí změnit a jméno soutěže je asi jediná jistota. Prozatím vypadá náš konstruktor takto.
sub new {
my($self, $liga) = @_;
my $f = {};
bless $f;
$f->{"liga"} = $liga;
return $f;
}
Získání zdrojového kódu
Prvním úkolem, který by měl modul Livescore učinit na základě požadavku od uživatele je získání dat. Data získáme na základě položky liga v objektu. Tato funkce nebude veřejná (resp. zdokumentovaná). Jejím úkolem bude vrátit data, o jejichž zpracování se postará zase někdo další.
Jak ale stáhneme data z webu? Nejjednodušší je prohledat CPAN. Jedním z modulů, který to umí je WWW::Mechanize, jež obsahuje metodu get($url).
use WWW::Mechanize;
Nyní můžeme napsat poměrně jednoduchou metodu ziskej_zdrojovy_kod. Je třeba si uvědomit, že dříve nebo později ji budeme muset přepsat kvůli perzistenci. Zatím to však řešit nebudeme.
sub ziskej_zdrojovy_kod {
my($self, $liga) = @_;
my $url;
my $zdroj = undef;
$url = "http://www.livescore.com/default.dll?page=$liga";
my $mech = WWW::Mechanize->new();
$zdroj = ($mech->get($url))->{"_content"};
return $zdroj;
}
Extrakce dat
Toto bude možná nejtvrdší oříšek celé aplikace. Co všechno budeme potřebovat za data? Nahlédněme do zdrojového kódu. Vidíme, že lze získat toto.
- účastníci zápasu
- případné skóre
- soutěž a země
- minuta u probíhajícího zápasu
- to, zda se zápas hraje
- čas výkopu
- protože budeme potřebovat i odkaz na detail zápasu, musíme uchovat ID zápasu a jméno soutěže tak, jak je uvedeno v odkazu
Úkolem je vytvořit na základě staženého zdrojového kódu pole hashů, které bude obsahovat zmíněné informace o jednotlivých zápasech. Bude to mechanická práce, ovšem i tu je dobré si ozkoušet.
Tato metoda bude veřejná. To znamená, že uživatel bude nucen volat při použití modulu Livescore nejprve konstruktor a následně metodu ziskej_zapasy_dane_ligy, kterou právě píšeme. Díky tomu si sám uživatel bude řídit, kdy data aktualizovat. Pro jednoduchost metoda vrátí seznam vyhovujících zápasů, se kterým bude nakládat dle uvážení uživatel. Zápasy tak nebudou součástí objektu.
Podíváme-li se na zdrojový kód, zjistíme, že to nebude vůbec tak jednoduché, protože každý zápas může být zobrazen v několika formátech. Pokud nejsou dostupné žádné podrobné informace k zápasu, nalezneme jako jeho reprezentaci ve zdrojovém kódu z livescore.com toto.
<tr bgcolor="#dfdfdf"><td width="45" height="18"> 23:00</td><td align="right"
width="118">Genemuiden</td><td align="center" width="50">? - ?</td><td width="118">FC
Omniworld</td></tr><tr><td colspan="4" height="1"></td></tr>
Pokud však již byla zaznamenána branka nebo jiná událost, vytvoří uvnitř odkaz a rázem se celý zdrojový kód pro zápas změní.
<tr><td colspan="4" height="1"></td></tr><tr bgcolor="#dfdfdf"><td width="45"
height="18"> FT</td><td align="right" width="118">Blackburn R.</td><td
align="center" width="50"><a class="scorelink" target="match_details"
onclick="window.open('','match_details','width=400,height=239,menubar=no,status=no,location=no,
toolbar=no,scrollbars=no,resizable=yes')" href="/default.dll/Game?comp=england1&game=359276">4
- 2</a></td><td width="118">Manchester C.</td></tr><tr><td colspan="4"
height="1"></td></tr>
Nehledě na to, že k zápasu musíme přidávat další dvojici údajů, která je rozmístěna mezi zápasy. Jsou to datum a čas výkopu a soutěž. Čas výkopu získáme z tohoto úseku kódu. Navíc může být čas změnen lokálně u jednotlivých zápasů.
<tr bgcolor="#333333"><td class="match-light" width="45" height="18"> 13:55</td><td
class="match-light" align="right" width="286" colspan="3">October 19 </td></tr>
A nakonec jméno soutěže a stát získáme odtud.
<tr bgcolor="#333333"><td class="title" colspan="4" height="18"> <b>England</b> -
League Cup</td></tr>
Všechny tyto úseky se v podstatě náhodně vyskytují uvnitř staženého zdrojového kódu. Je tedy třeba postupně projít celý zdrojový kód a hledat výskyty zmíněných úseků. Přitom musíme dodržet jejich pořadí, protože jinak bychom nebyli schopni správně určit čas výkopu a soutěž.
Všimněme si, že každý údaj - ať již datum konání, národní soutěž a zápas jsou vždy na jednom řádku. Tudy povede cesta. Alespoň pro naše řešení.
Napišme si tedy podrobnější postup extrakce dat.
- Než začneme, je třeba získat zdrojový kód pomocí funkce ziskej_zdrojovy_kod, kterou již máme.
- Nejprve ze zdrojového kódu vyextrahujeme všechny řádky. Řádek vždy začína tagem <tr> a končí </tr>. Musíme přitom zachovat jejich pořadí.
- Dále budeme řádky třídit a získávat z nich data. Určíme tedy, jakou informaci řádek poskytuje. Máme 4 možnosti.
- Obsahuje informaci o zápase. Získáme odtud názvy týmů, skóre, minutu a případně změníme čas výkopu. Získaná si případně upravíme data k obrazu svému a všechny údaje zapíšeme do pole zápasů.
- Obsahuje informaci o čase pro nadcházející zápasy - změníme obsah proměnných uchovávajících čas.
- Obsahuje informaci o soutěži pro nadcházející zápasy - změníme obsah proměnných uchovávajících soutěž.
- Neobsahuje žádnou z hledaných informací a je pro nás bezcenný
- Vrátíme pole zápasů.
Nejprve získáme zdrojový kód pomocí již napsané metody.
sub ziskej_zapasy_dane_ligy {
my($self) = @_;
my @zapas; #bude obsahovat informace o zápasech
my $zdroj = $self->ziskej_zdrojovy_kod($self->{"liga"});
#hlavní část funkce
return @zapas;
}
Z něj odseparujeme veškeré úseky, které začínají <tr> a končí </tr>. Jsou to pro nás potenciální užitečné informace.
my $i=0;
my @radek;
$radek[$i++] = $1 while $zdroj =~ /(<tr.*?>.*?<\/tr>)/g;
Další bod je úspěšně za námi. Teď ale přijde na řadu to nejhorší. Každý řádek budeme muset pečlivě prozkoumat.
for (@radek){
#extrakce
}
Hlavním "work horse" tohoto problému budou regulární výrazy. Pomocí nich zajistíme veškerou extrakci.
Předně budeme zjišťovat, zda řádek je pro nás cenná informace. Jak to poznáme? Vzpomeňme na úryvky ze zdrojového kódu na začátku tohoto oddílu. Budeme muset vytvořit pro každý úsek vzor a ten porovnat s řádkem. Bude to vypadat takto.
if ($_ =~ /regex1|regex2|regex3/g){
#kód je pro nás cenný; zpracujeme ho
}
#kód nás nezajímá, přejdeme na další iteraci
Musíme napsat následující tři regulární podvýrazy.
- regulární výraz, kterému vyhoví řádek obsahující informaci o zápase (na obrázku žlutá)
- regulární výraz, kterému vyhoví řádek obsahující informaci o datu a čase výkopu (červená)
- regulární výraz, kterému vyhoví řádek obsahující informaci o soutěži (modrá)
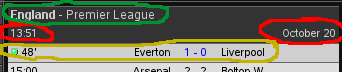
druhy řádků, ze kterých chceme získat data
Tento regulární výraz tady nebudeme kompletně odvozovat, protože je to spíš manuální práce a popis by zabral několik stránek. Je třeba najít co nejvíc variant formátu těchtýž dat ve staženém zdrojovém kódu a pokusit se vytvořit regulární výraz, který je všechny zahrne. Každý řádek se zápasem na www.livescore.com má totiž trochu jiný formát a tento rozdíl musíme vyeliminovat.
Úkol tedy zní: Nalezněme regulární výraz, kterému vyhoví, všechny řádky obsahující informaci o zápase. Stejně potom budeme postupovat i u získávání času a soutěže.
Uveďme si několik obecných metod, kterými lze regulární výraz tvořit.
- Všechny údaje, které chceme extrahovat dáme do závorek
- Pokud se v jedné variantě objeví navíc nějaký kód (např. u hrajícího zápasu se zobrazuje vždy obrázek blikající tečky), použijeme na něj toto uvození: (?:regex)?.
- Parametry tagů, které se mohou lišit je dobré nahradit sekvencí (?:[^>]*). Místo <td parametry> tak napíšeme do regulárního výrazu <td(?:[^>]*)>.
Pod nějaké době získáme tento nebo jemu podobný regulární výraz pro řádek se zápasem.
(?:>tr bgcolor=\"#......\">>td(?:[^>]*)> (?:<(i)mg[^>]*> )?([\w\:.]*)'?<\/td>>td
(?:[^>]*)>(.[^>]*)>\/td>>td(?:[^>]*)>(?:\>a class=\"scorelink\" target=\"match_details\"
onclick=\"window.open\('','match_details','width=400,height=\d*,menubar=no,status=no,lo
cation=no,toolbar=no,scrollbars=no,resizable=yes'\)\" href=\"\/default.dll\/Game\?comp=
(\w*)&game=(\d*)\">)?([?\d]+) - ([?\d]+)(?:>\/a>)?>td>>td width=\"118\">(.[^<]*)<\/td><\/tr>)
Podobně získáme další dva regulární výrazy, spojíme je alternací a vepíšeme do podmínky.
if ($_ =~ /(?:>tr bgcolor=\"#......\">>td(?:[^>]*)> (?:<(i)mg[^>]*> )?([\w
\:.]*)'?<\/td>>td(?:[^>]*)>(.[^>]*)>\/td>>td(?:[^>]*)>(?:\>a class=\"scorelink\" targe
t=\"match_details\" onclick=\"window.open\('','match_details','width=400,height=
\d*,menubar=no,status=no,location=no,toolbar=no,scrollbars=no,resizable=yes'\)\
" href=\"\/default.dll\/Game\?comp=(\w*)&game=(\d*)\">)?([?\d]+) - ([?\d]+)(?:>\/
a>)?>td>>td width=\"118\">(.[^<]*)<\/td><\/tr>)|(?:>tr bgcolor=\"#......\">>td class=\"tit
le\" colspan=\"4\" height=\"18\"> >b>([^>]*)>\/b> - ([^>]*)>\/td>>\/tr>)
|(?:>tr bgcolor=\"#......\">>td class=\"match-light\" width=\"45\" height=\"18\"> ([^>]*
)?>\/td>>td class=\"match-light\" align=\"right\" width=\"286\" colspan=\"3\">(\w+) (\d
+) >\/td>>\/tr>)/g){
#zpracování dat
}
Poznámka - kvůli sazbě byly výše uvedené zdrojové kódy rozděleny do řádků. Znaky nových řádků ovšem do programu nepatří.
Nyní máme jistotu, že data na řádku, jež vyhovuje výše uvedenému regulárnímu výrazu jsou pro nás cenná. Nyní bychom se měli zamyslet, jak je správně dostaneme do proměnných. Zde je tabulka extrahovaných hodnot.
| Typ získané informace | Proměnná | Informace |
| o zápase | $1 | hraje se? |
| $2 | před výkopem čas výkopu, po výkopu minuta | |
| $3 | název domácího týmu | |
| $4 | (pouze je-li dostupná nějaká událost) liga podle livescore.com | |
| $5 | (pouze je-li dostupná nějaká událost) ID zápasu podle livescore.com | |
| $6 | skóre domácích | |
| $7 | skóre hostů | |
| $8 | název hostujícího týmu | |
| o soutěži | $9 | název státu |
| $10 | název soutěže | |
| o času výkopu | $11 | čas výkopu nebo poslední aktualizace |
| $12 | měsíc výkopu | |
| $13 | den výkopu |
Tyto informace uložíme do výsledného pole. Ještě předtím však několik údajů pozměníme. Jsou to většinou věci, které bychom dělali až během testování výsledného programu, ale protože je na to třeba delší zkušenost s daty na livescore.com, uveďme je pro lepší orientaci hned.
| Proměnná, kterou budeme upravovat | Podmínka úpravy | Nová hodnota |
| $1 | pokud obsahuje i | změníme na PROBIHA |
| $1 | pokud není definováno | změníme na PRED_VYKOPEM nebo UKONCEN podle probíhající minuty |
| $2 | pokud obsahuje čas výkopu | změníme na -- |
| $2 | pokud obsahuje delší řetězec - tedy AET, Pen., Postp. nebo Susp. | zaměníme za dvojznaková OT, PN, XO a XS |
| $3 a $8 | pokud obsahuje & | zaměníme tento podřetězec za & |
| $6 a $7 | pokud je skóre "?" | nahradíme za "-" |
| $11 | pokud získáme čas v proměnné $2 | má vyšší prioritu než $10 |
| $12 | vždy | anglický název měsíce nahradíme jeho pořadovým číslem |
U proměnné $1, nahrazujeme původní hodnotu konstantou. Tyto konstanty je třeba definovat.
use constant {
UKONCEN => 0,
PROBIHA => 1,
PRED_VYKOPEM => 2
};
Nyní nám zbývá vytvořit z obou tabulek zdrojový kód. Pokud tedy narazíme na řádek s informacemi o soutěži (zjistíme to tak, že jsou definované proměnné $9 a $10), nastavíme proměnné $soutez a $zeme.
if($9){
$zeme = $9;
$soutez = $10;
}
V případě řádku s informacemi o čase (jsou definované proměnné $11 až $13), nastavíme proměnné $cas, $den a $mesic. $mesic zkonvertujeme (ne příliš elegantně) na pořadové číslo příslušného měsíce.
if($12){
$cas = $11;
$mesic = $12;
$den = $13;
$mesic eq "January" and $mesic=1;
$mesic eq "February" and $mesic=2;
$mesic eq "March" and $mesic=3;
$mesic eq "April" and $mesic=4;
$mesic eq "May" and $mesic=5;
$mesic eq "June" and $mesic=6;
$mesic eq "July" and $mesic=7;
$mesic eq "August" and $mesic=8;
$mesic eq "September" and $mesic=9;
$mesic eq "Octomber" and $mesic=10;
$mesic eq "November" and $mesic=11;
$mesic eq "December" and $mesic=12;
}
A pak zde máme informace o zápase. Na tomto řádku nejen, že nastavíme proměnné, ale všechna data zaznamenáme. Navíc musíme udělat větší množství úprav v datech. Je třeba vyřešit ampérsandy a obsah proměnné $skore. Dále je třeba upravit obsah proměnné $minuta a $hraje_se.
if($1){
my $minuta=$1;
my $tym1 = $2;
my $tym2 = $7;
my $skore1 = $5;
my $skore2 = $6;
my $liga = $3;
my $id = $4;
$tym1 =~ s/(&)/&/;
$tym2 =~ s/(&)/&/;
if($skore1 eq "?"){$skore1 = $skore2 = "-";}
if($minuta =~ /^\d\d:\d\d$/){$cas = $minuta; $minuta="--";}
$minuta eq "AET" and $minuta = "OT";
$minuta eq "Pen." and $minuta= "PN";
$minuta eq "Postp." and $minuta= "XO";
$minuta eq "Susp." and $minuta= "XS";
if($1 eq "i"){$hraje_se = PROBIHA;}
elsif($minuta eq "--"){$hraje_se = PRED_VYKOPEM;}
else{$hraje_se = UKONCEN;}
push(@zapas, {
"tym1" => $tym1,
"tym2" => $tym2,
"skore1" => $skore1,
"skore2" => $skore2,
"liga" => "$zeme: $soutez",
"odkaz_liga"=> $liga,
"odkaz_idzapasu" => $id,
"minuta" => $minuta eq "" ? "??" : $minuta,
"vykop" => $den ? "$den.$mesic $cas" : "KONEC",
"hraje_se" => $hraje_se
});
}
A jsme hotovi. Nyní náš modul již umí získat informace o zápasech.
return @zapas;