|
|
 Perl (82) - CGI - první skripty
Perl (82) - CGI - první skripty
![]() Napíšeme první CGI skript a vysvětlíme jeho strukturu.
Napíšeme první CGI skript a vysvětlíme jeho strukturu.
29.6.2009 01:00 | Jiří Václavík | read 18217×
DISCUSSION
Na úvod poznamenejme, že CGI skripty mohou být napsané prakticky v jakémkoliv programovacím jazyce, který je na serveru (nebo počítači z něj dostupném) interpretovatelný. Lze použít například Perl, Python, Bash, C a máte-li nějaký vlastní jazyk, tak ten také. Právě s Perlem bylo CGI v minulosti spojováno velmi často.
Archiv CPAN nabízí několik modulů usnadňujících tvorbu CGI skriptů. O několik dílů později se jednomu takovému s názvem CGI budeme věnovat. Nyní však budeme postupovat bez podpůrných modulů, protože tak lze snáze problematiku pochopit.
První CGI skript
V každém nekompilovaném CGI skriptu musíme uvést několik věcí.
- pomocí čeho zpracovat skript (například pomocí Perlu - informace pro webový server)
- co je výsledkem našeho skriptu (HTML soubor, text, obrázek, atd. - informace pro nějaký klientův prohlížeč)
- samotný skript
Úvodní řádek určuje cestu k interpretu a vypadá následovně.
#!/cesta/k/interpretu
Dále je třeba pro webový prohlížeč na straně klienta uvést hlavičky dokumentu dle příslušného HTTP standardu. Zde uvedeme bez podrobnějšího vysvětlování jen to, co je nezbytně nutné.
Zopakujme, že nyní jsme v druhém bodu a uvedeme tedy, jaké povahy je výsledek interpretování. Je nutné specifikovat MIME typ zprávy. Zde záleží na tom, co budeme chtít, aby náš CGI skript generoval.
MIME je typ dat. Mezi základní kategorie datových typů patří application, audio, example, image, message, model, multipart, text a video. Každý z nich pak může nabývat různých podtypů. Pro čistý text použijeme MIME text/plain, pro text formátovaný v HTML text/html apod. Více o MIME typech lze nalézt na www.iana.org.
MIME typ uvedeme v hlavičce s názvem Content-type. Bude-li výsledkem CGI skriptu HTML dokument, pak jako druhý řádek CGI skriptu napíšeme toto.
print "Content-type: text/html\n\n";
Protože HTTP protokol vyžaduje prázdný řádek mezi hlavičkou a tělem zprávy, je mezi nimi sekvence "\n\n". Tím jsme dokončili část s hlavičkami a nyní tedy můžeme začít psát vlastní tělo programu.
Protože jsme uvedli jako MIME typ text/html, bude náš skript generovat HTML dokument - měli bychom tedy dodržet HTML strukturu (přesněji řečeno, webový prohlížeč to předpokládá a bude se podle toho chovat). Abychom přidali stránce "dynamičnost", zobrazíme aktuální čas.
my $now = localtime;
print << "HTML";
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<HTML>
<HEAD>
<TITLE>Hello World</TITLE>
</HEAD>
<BODY>
<H2>Hello world</H2>
$now
</BODY>
</HTML>
HTML
Nyní tento program spustíme nejprve v příkazovém řádku.
$ perl /usr/local/apache2/cgi-bin/hello.cgi
Content-type: text/html
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<HTML>
<HEAD>
<TITLE>Hello World</TITLE>
</HEAD>
<BODY>
<H2>Hello world</H2>
Sun Jun 18 19:02:38 2009
</BODY>
</HTML>
$
V podstatě se stalo přesně to, co bychom očekávali. Vygeneroval se nám HTML dokument s nějakou úvodní hlavičkou navíc.
Nyní můžeme zkusit spustit skript v prohlížeči. Pokud zadáme jako umístění /usr/local/apache2/cgi-bin/hello.cgi, zobrazí se zdrojový kód CGI skriptu (nikoliv jeho výstup a už vůbec ne interpretovaný HTML dokument).
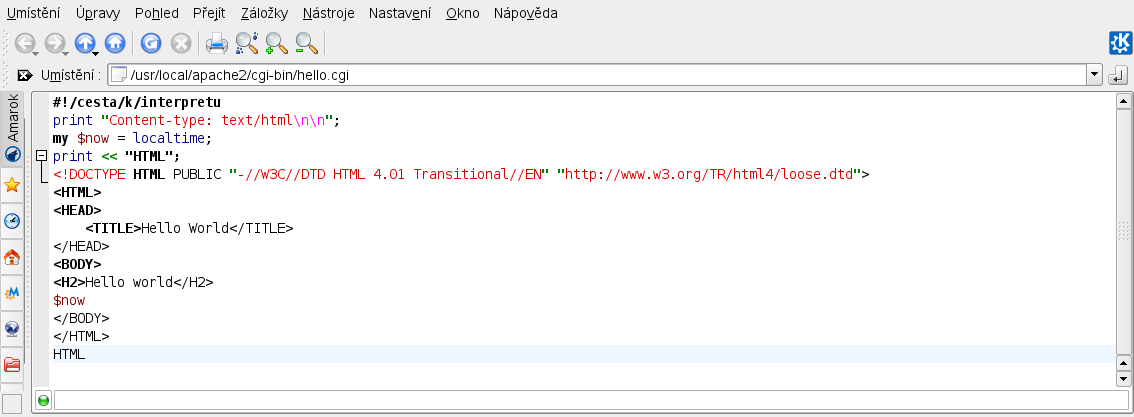
Statické zobrazení obsahu souboru
Nyní spustíme CGI skript prostřednictvím webového serveru. Nastartujeme tedy webový server a do prohlížeče zadáme příkaz http://localhost/cgi-bin/hello.cgi. Pokud jde vše, jak má, měli bychom spatřit jednoduchou dynamicky vygenerovanou HTML stránku.
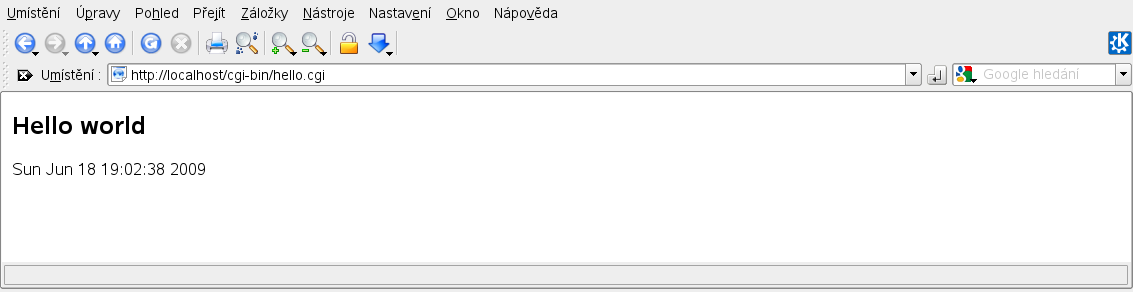
Dynamicky vygenerovaný HTML dokument
Tento CGI program je velmi jednoduchý. Hlavním důvodem je, že od uživatele nepřijímá žádná data a zpracovává pouze informaci serveru o aktuálním čase.
Pokud bychom zadali do hlavičky Content-type místo text/html například text/plain, práce pro server by zůstala stejná. Lišila by se však interpretace výsledku v prohlížeči. Jak by se takový dokument zobrazil, si můžete vyzkoušet nebo se podívat na obrázek.
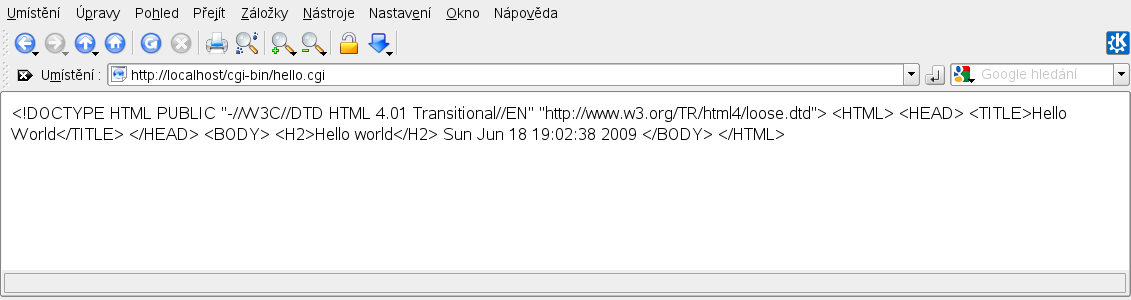
Dynamicky vygenerovaný textový dokument
Pro představu doplňme, že hlaviček je mnohem více, než jen povinná výše používaná hlavička Content-type. A dokonce oproti předchozímu ani hlavička Content-type nemusí být uvedena. V takovém případě však je nutné uvést hlavičku Location, jejímž parametrem je odkaz na umístění. Ostatní hlavičky jsou volitelné. Zde máme příklad Location hlavičky, která přesměruje na www.linuxsoft.cz.
print "Location: http://www.linuxsoft.cz\n\n";
Ladění CGI skriptů
Než začneme psát další CGI skripty, je užitečné mít na vědomí, že CGI skript je stále perlový skript a že ho je možné stále spustit v textovém režimu. Zdůrazňujeme to proto, že WWW prohlížeč nám neukáže standardní chybový výstup a v případě chyby bychom mohli být překvapeni, proč se nic neděje.
Absence chybového výstupu je značný hendikep, neboť hledat chybu bez jakýchkoliv hlášení je mnohdy téměř nemožný úkol.
Dobrou a jednoduchou metodou pro ladění je spuštění CGI skriptu příkazem perl a sledovat výstup v konzoli. Jinou možností je kontrola log souborů apache. V /usr/local/apache2/logs/error_log bychom měli najít chybový výstup našich CGI skriptů.
Proměnné prostředí
Webový server obvykle nastavuje pro CGI skript některé speciální proměnné prostředí. Odtud můžeme čerpat zejména informace o serveru, ale jsou zde i položky, které charakterizují požadavek uživatele. Proměnné prostředí nám jsou v CGI programu přístupné z hashe %ENV. Tyto proměnné prostředí uvádí následující tabulka.
Je nutno podotknout, že záleží pouze na serveru, které proměnné budou dostupné. Také se mohou názvy proměnných v detailech lišit. Informace o serveru obvykle začínají prefixem SERVER_. Data o uživateli, který zaslal požadavek, jsou zase dostupná přes REMOTE_.
| Proměnná | Hodnota |
| REQUEST_METHOD | metoda vstupu dat |
| QUERY_STRING | řetězec vstupních dat předaných metodou GET |
| CONTENT_TYPE | typ dat od uživatele |
| CONTENT_LENGTH | maximální délka vstupu pro metodu POST |
| GATEWAY_INTERFACE | verze CGI ve formátu CGI/verze |
| AUTH_TYPE | způsob autentifikace uživatele |
| REQUEST_URI | URL bez doménového jména |
| SCRIPT_FILENAME | cesta ke skriptu od adresáře / |
| SCRIPT_NAME | cesta ke skriptu z pohledu serveru |
| REMOTE_ADDR | IP ppočítače uživatele |
| REMOTE_HOST | doménové jméno počítače uživatele |
| REMOTE_PORT | port uživatele |
| SERVER_ADDR | IP serveru |
| SERVER_ADMIN | kontakt na administrátora serveru |
| SERVER_NAME | doménové jméno serveru |
| SERVER_PORT | port serveru |
| SERVER_PROTOCOL | protokol a verze |
| SERVER_SOFTWARE | jméno a verze serveru a modulů |
Nastavují se také proměnné podle přijatých hlaviček. Jsou tak dostupné například HTTP_ACCEPT, HTTP_ACCEPT_CHARSET, HTTP_ACCEPT_ENCODING, HTTP_ACCEPT_LANGUAGE, HTTP_CONNECTION, HTTP_COOKIE, HTTP_HOST, HTTP_USER_AGENT.
Pro konkrétnější představu o tom, jakých hodnot jednotlivé proměnné nabývají si předveďme jednoduchý CGI program, který vypíše obsahy proměnných prostředí.
#!/usr/bin/perl
print "Content-type: text/plain\n\n";
foreach $p (sort keys %ENV) {
$h = $ENV{$p};
print "$p=$h\n";
}
CGI a bezpečnost
Při psaní webových aplikací si je dobré uvědomit, že každá neošetřená hodnota, která přijde od uživatele, je nakažená. Vždy předtím, než začneme pracovat s přijatými daty, je musíme vyléčit. Aby bylo ošetřování vynuceno, doporučuje se skripty spouštět s parametrem -T.
O nakaženém režimu již v rámci seriálu vyšel zvláštní díl.
|
|
||
|
DISCUSSION
For this item is no comments. |
||
|
Add comment is possible for logged registered users.
|
||
| 1. |
Pacman linux Download: 6007x |
| 2. |
FreeBSD Download: 10193x |
| 3. |
PCLinuxOS-2010 Download: 9676x |
| 4. |
alcolix Download: 12372x |
| 5. |
Onebase Linux Download: 11178x |
| 6. |
Novell Linux Desktop Download: 0x |
| 7. |
KateOS Download: 7504x |
| 1. |
xinetd Download: 3765x |
| 2. |
RDGS Download: 937x |
| 3. |
spkg Download: 6799x |
| 4. |
LinPacker Download: 12090x |
| 5. |
VFU File Manager Download: 4119x |
| 6. |
LeftHand Mała Księgowość Download: 8526x |
| 7. |
MISU pyFotoResize Download: 3869x |
| 8. |
Lefthand CRM Download: 4664x |
| 9. |
MetadataExtractor Download: 0x |
| 10. |
RCP100 Download: 4257x |
| 11. |
Predaj softveru Download: 0x |
| 12. |
MSH Free Autoresponder Download: 0x |
 linuxsoft.cz
| Design: www.megadesign.cz
linuxsoft.cz
| Design: www.megadesign.cz