
ARCHIV
 MySQL (23) - relace 1:N a N:N
MySQL (23) - relace 1:N a N:N
Co znamenají zkratky 1:N a N:N? Jak souvisejí se psaním spojení a proč by nestačilo mít jen jeden typ spojení? To všechno se dozvíte v dnešním díle seriálu o MySQL.
3.6.2005 07:00 |
Petr Zajíc
| Články autora
| přečteno 58685×
Zatím jsme v seriálu rozebírali taková spojení, při nichž šlo o dvě
tabulky. Napsal jsem ale rovněž, že principielně lze spojit i více
tabulek. Ačkoli to nepředstavuje žádný syntaktický zádrhel, pro
začátečníky v oblasti databází bývá někdy problém pochopit logiku
takových spojení. Proto se jim dnes budeme trochu věnovat.
Spojení 1:N
Toto spojení jsme vlastně již probrali. Tajemnou zkratkou "1:N" se v
databázovém světě rozumí spojení, kde jeden záznam v "hlavní" tabulce
obsahuje teoreticky libovolný počet odpovídajících záznamů v
"podřízené" tabulce. (Teoreticky libovolný počet zahrnuje rovněž nulu).
Připomeňme také, že k vyjádření takového spojení se používá:
- klauzule LEFT JOIN (nebo RIGHT JOIN) v případě, kdy chceme zobrazit všechny řádky z "hlavní" tabulky bez ohledu na to, zda existují nějaké řádky v "podřízené" tabulce
- klauzule INNER JOIN v případě, kdy chceme zobrazit pouze řádky v "hlavní" tabulce, které mají nějaké související záznamy v tabulce "podřízené"
V praxi existuje celá řada situací, na níž lze toto schéma uplatnit.
Pro osvěžení si některá připomeňme:
- Jedna faktura může mít celou řadu položek ("hlavní" tabulka obsahuje záhlaví faktury, "podřízená" obsahuje položky)
- Jedna síť může obsahovat řadu počítačů ("hlavní" tabulka obsahuje seznam sítí, "podřízená" obsahuje seznam počítačů v těchto sítích)
- Jeden zaměstnanec se může starat o řadu zákazníků ("hlavní" tabulka obsahuje seznam zaměstnanců, "podřízená" obsahuje seznam zákazníků)
Celá situace se dá poměrně snadno znázornit graficky. Na obrázku
níže můžete vidět, jak by vyladalo spojení mezi tabulkou faktur a
jejich položek.
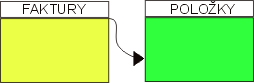
Kdybychom něco takového chtěli zapsat pomocí SQL, nebude to problém:
select * from faktury
join polozky on faktury.id = polozky.faktura;
Spojení N:N
Co je špatného na modelu 1:N, že potřebujeme vymyšlet něco dalšího?
Na modelu samotném není špatného nic. Problém spočívá v tom, že pro
reálný svět tento model zkrátka nepostačuje. Vraťme se na chvíli k naší
imaginární databázové aplikaci, která má mapovat provoz v knihovně. Jak
byste zmapovali proces půjčování knih? Je pravda, že jeden čtenář si
může půjčit více knih, ALE zároveň je pravda, že více čtenářů si může
půjčit stejnou knihu (dejme tomu v různém období). Vztah mezi knihami a
čtenáři tedy není 1:N, ale N:N.
Realizovat něco takového pomocí dvou tabulek v reálné databázi
většinou nejde. Takový vztah se obyčejně programuje pomocí další, třetí
tabulky, která je spojena s oběma původními tabulkami. S každou
tabulkou má vztah 1:N a celé to dokáže simulovat spojení N:N. Protože
se to asi dá jen těžko představit, posloužím zase malým obrázkem:

Je dobré si "prostřední" tabulku nějak smysluplně nazvat, i když to někdy nebude tak úplně jednoduché. My bychom si ji mohli nazvat například "výpůjčky". Z toho je krásně vidět, jak je relace N:N "rozbita" na dvě relace 1:N. Platí totiž:
- mnoho různých čtenářů si může půjčit mnoho různých knih (N:N)
- jedna kniha může být půjčena mnohokrát (1:N mezi knihami a výpůjčkami)
- jeden čtenář může přijít do knihovny vícekrát za život a něco si půjčit (1:N mezi čtenáři a výpůjčkami)
V praxi to často bývá tak, že "prostřední" tabulka neslouží pouze
jako technický prostředek k realizaci spojení N:N, ale že obsahuje i
nějaké smysluplné informace. Například si dokážu představit, že by
tabulka výpůjček docela dobře mohla obsahovat datum půjčení a datum
vrácení každé publikace. To totiž nepatří logicky ani do tabulky knih,
ani do tabulky čtenářů.
Pozn.: Vidíte mimochodem, jak nesmírně je toto řešení pružné? Umožňuje například postihnout situaci, kdy čtenář nevrátí všechny knihy, které má půjčené ve stejném termínu. Protože pro každou kombinaci kniha-čtenář existuje řádek v tabulce výpůjček, lze to pohodlně zapsat.
V praxi bychom tedy mohli pomocí výše uvedené průpravy například sestavit seznam právě vypůjčených knih:
select knihy.nazev,
ctenari.prijmeni from
knihy join vypujcky on knihy.id = vypujcky.kniha
join ctenari on vypujcky.ctenar = ctenari.id
where vypujcky.vracenodne is null;
Poznámky ke spojením
Zejména spojení N:N vyžadují určitou představivost ze strany
programátora. Během let, kdy jsem programoval databázové aplikace, jsem
si sestavil několik tipů, které se vám možná také budou hodit:
- Změnit relaci 1:N na N:N v pozdější fázi vývoje může být docela problém. Je lepší pečlivě si promyslet návrh databáze, než ji začnete tvořit.
- Mnoho spojení N:N samozřejmě znamená zvýšení obemu dat v databázi a zároveň snížení výkonu. Umožňuje však ukládat data pružně a do určité míry reagovat na změny v logice uložení dat. Výhody a nevýhody jsou jak už to bývá protichůdné, takže je třeba pečlivě vybírat.
- Jestliže nevíte, zda bude mezi dvěma tabulkami vztah 1:N nebo N:N, stop! Je to důležité a obyčejně je to třeba hned promyslet. Leckdy se problém dá převést z počítačové řeči do jazyka, jimž mluví zákazník (třeba čeština ;-)))) a zeptat se.
- Hotová katastrofa vznikne, když se programátor snaží pomocí 1:N a N:N relací popsat procesy, jejichž toku dostatečně nerozumí (může se jednat například o aplikaci skladového hospodářství se složitým způsobem kompletace výrobků). Nezřídka je pak nutné celý návrh zahodit a začít znovu, pozor na to.
- Jestliže máte duplicitní údaje ve dvou tabulkách, které spolu
jsou v relaci 1:N, možná že měly být v relaci N:N. Možná je čas to
předělat, i když to bude složité. Do budoucna to může ušetřit čas,
výkon a náklady.
Předchozí Celou kategorii (seriál) Další
MySQL (2) - Instalujeme databázi MySQL
MYSQL (3) Instalujeme MySQL podruhé
MySQL (4) - něco terminologie
MySQL (5) - tajuplné SQL
MySQL (6) - Ukládáme řetězce
MySQL (7) - hrátky s čísly
MySQL (8) - Ukládání datumů
MySQL (9) - Další datové typy
MySQL (10) - tvorba databáze. Základy DDL
MySQL (11) - vytváříme tabulky
MySQL (12) - tipy k tvorbě tabulek
MySQL (13) - Vkládáme data
MySQL (14) - Upravujeme data
MySQL (15) - Odstraňujeme data
MySQL (16) - Tipy a triky k manipulaci s daty
MySQL (17) - vybíráme data
MySQL (18) - Filtrujeme data
MySQL (19) - Řadíme data
MySQL (20) - spojení více tabulek
MySQL (21) - klauzule JOIN
MySQL (22) - tipy a triky ke spojování tabulek
MySQL (24) - Seskupujeme záznamy
MySQL (25) - hrátky se seskupenými záznamy
MySQL (26) - Poddotazy
MySQL (27) - Složitější dotazy
MySQL (28) - Dotazy pro pokročilé
MySQL (29) - Vracení nejvyšších záznamů
MySQL (30) - průběžné součty
MySQL (31) - Indexy
MySQL (32) - ještě k indexům
MySQL (33) - Příkaz UNION
MySQL (34) - větvení kódu a pivotní tabulky
MySQL (35) - vestavěné funkce
MySQL (36) - Regulární výrazy
MySQL (37) - použití fulltextového vyhledávání
MySQL (38) - Fulltext a praxe
MySQL (39) - typy tabulek v MySQL
MySQL (40) - další typy tabulek
MySQL (41) - Transakce
MySQL (42) - ještě k transakcím
MySQL (43) - Uložené procedury
MySQL (44) - parametry uložených procedur
MySQL (45) - větvení kódu uložených procedur
MySQL (46) - Triggery
MySQL (47) - Triggery a praxe
MySQL (48) - UDF
MySQL (49) - pohledy
MySQL (50) - Pohledy podruhé
MySQL (51) - Metadata
MySQL (52) - A co zálohování?
MySQL (53) - SELECT INTO OUTFILE
MySQL (54) - zálohování MySQL z webu
MySQL (55) - zálohování MySQL z pohledu správce
MySQL (56) - Obnova zálohovaných dat
MySQL (57) - Ach, ta čeština
MySQL (58) - čeština v praxi
MySQL (59) - české řazení
MySQL (60) - řádkový klient
MySQL (61) - Oprávnění
MySQL (62) - Oprávnění podruhé
MySQL (63) - jemné nastavení práv
MySQL (64) - nad dotazy čtenářů
MySQL (65) - Ladíme server
MySQL (66) - Ještě k ladění serveru
MySQL - (67)
MySQL (68) - Závěr
MySQL (69) - Prepared Statements
Předchozí Celou kategorii (seriál) Další
|
Nejsou žádné diskuzní příspěvky u dané položky. Příspívat do diskuze mohou pouze registrovaní uživatelé. | |
28.11.2018 23:56 /František Kučera
Prosincový sraz spolku OpenAlt se koná ve středu 5.12.2018 od 16:00 na adrese Zikova 1903/4, Praha 6. Tentokrát navštívíme organizaci CESNET. Na programu jsou dvě přednášky: Distribuované úložiště Ceph (Michal Strnad) a Plně šifrovaný disk na moderním systému (Ondřej Caletka). Následně se přesuneme do některé z nedalekých restaurací, kde budeme pokračovat v diskusi.
Komentářů: 1
12.11.2018 21:28 /Redakce Linuxsoft.cz
22. listopadu 2018 se koná v Praze na Karlově náměstí již pátý ročník konference s tématem Datová centra pro business, která nabídne odpovědi na aktuální a často řešené otázky: Jaké jsou aktuální trendy v oblasti datových center a jak je optimálně využít pro vlastní prospěch? Jak si zajistit odpovídající služby datových center? Podle jakých kritérií vybírat dodavatele služeb? Jak volit vhodné součásti infrastruktury při budování či rozšiřování vlastního datového centra? Jak efektivně datové centrum spravovat? Jak co nejlépe eliminovat možná rizika? apod. Příznivci LinuxSoftu mohou při registraci uplatnit kód LIN350, který jim přinese zvýhodněné vstupné s 50% slevou.
Přidat komentář
6.11.2018 2:04 /František Kučera
Říjnový pražský sraz spolku OpenAlt se koná v listopadu – již tento čtvrtek – 8. 11. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma umění a technologie, IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
4.10.2018 21:30 /Ondřej Čečák
LinuxDays 2018 již tento víkend, registrace je otevřená.
Přidat komentář
18.9.2018 23:30 /František Kučera
Zářijový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 20. 9. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
9.9.2018 14:15 /Redakce Linuxsoft.cz
20.9.2018 proběhne v pražském Kongresovém centru Vavruška konference Mobilní řešení pro business.
Návštěvníci si vyslechnou mimo jiné přednášky na témata: Nejdůležitější aktuální trendy v oblasti mobilních technologií, správa a zabezpečení mobilních zařízení ve firmách, jak mobilně přistupovat k informačnímu systému firmy, kdy se vyplatí používat odolná mobilní zařízení nebo jak zabezpečit mobilní komunikaci.
Přidat komentář
12.8.2018 16:58 /František Kučera
Srpnový pražský sraz spolku OpenAlt se koná ve čtvrtek – 16. 8. 2018 od 19:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát jsou tématem srazu databáze prezentaci svého projektu si pro nás připravil Standa Dzik. Dále bude prostor, abychom probrali nápady na využití IoT a sítě The Things Network, případně další témata.
Přidat komentář
16.7.2018 1:05 /František Kučera
Červencový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 19. 7. 2018 od 18:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát bude přednáška na téma: automatizační nástroj Ansible, kterou si připravil Martin Vicián.
Přidat komentář
31.7.2023 14:13 /
Linda Graham
iPhone Services
30.11.2022 9:32 /
Kyle McDermott
Hosting download unavailable
13.12.2018 10:57 /
Jan Mareš
Re: zavináč
2.12.2018 23:56 /
František Kučera
Sraz
5.10.2018 17:12 /
Jakub Kuljovsky
Re: Jaký kurz a software by jste doporučili pro začínajcího kodéra?