
ARCHIV
 Perl (139) - Profilling - efektivní odhalování pomalých míst v programu
Perl (139) - Profilling - efektivní odhalování pomalých míst v programu
![]() Napsali jste program, který je pomalý? Nevíte si rady, jak ho zoptimalizovat? Pak zkuste profiler - nástroj, který odhalí, jaké části programu trvají nejděle.
Napsali jste program, který je pomalý? Nevíte si rady, jak ho zoptimalizovat? Pak zkuste profiler - nástroj, který odhalí, jaké části programu trvají nejděle.
27.8.2011 00:00 |
Jiří Václavík
| Články autora
| přečteno 12077×
Kdysi jsme se zabývali modulem Benchmark. To je vynikající nástroj pro případy, kdy potřebujeme výsledek typu porovnání rychlosti dvou podprogramů. Co když ale potřebujeme komplexní analýzu naší aplikace, která neběží tak rychle, jak bychom očekávali? Pak je třeba použít daleko silnější nástroje.
Mezi takové patří tzv. profilery, které dělají dynamickou analýzu běhu programu.
Existují profilery měřící výkon i profilery měřící použití paměti. Mohou fungovat tak, že měří větší úseky (podprogramy nebo nějaké vybrané části) nebo menší úseky (jednotlivé výrazy). Jejich výstupem je rozbor zdrojového kódu v různé formě, statistická analýza nebo něco jiného podle zaměření konkrétního nástroje.
Profiling a Perl
Perl má to štěstí, že existuje nástroj Devel::NYTProf, který zastane většinu běžně požadovaných úkolů.
$ cpan Devel::NYTProf
Příklad
Většinou se profiler používá na nějaké rozsáhlejší aplikace, které používají řadu modulů, kde tyto moduly používají jiné moduly atd. My si pro jednoduchost ukážeme běh profileru pouze na malém kousku kódu.
Minule jsme se zabývali efektivitou algoritmů na výpočet Fibonacciho posloupnosti. Zkusme se tématu věnovat dále. Podívejme se na následující trojici podprogramů.
use Memoize;
sub fibonacci_neopt {
my $n = shift;
return 1 if ($n <= 1);
return fibonacci_neopt($n - 1) + fibonacci_neopt($n - 2);
}
{
my @vypocitane;
sub fibonacci_opt {
my $n = shift;
return $vypocitane[$n] if defined $vypocitane[$n];
my $vysledek;
if ($n <= 1){
$vysledek = 1;
}
else {
$vysledek = fibonacci_opt($n - 1) + fibonacci_opt($n - 2);
}
return $vypocitane[$n] = $vysledek;
}
}
memoize("fibonacci_memoize");
sub fibonacci_memoize {
my $n = shift;
return 1 if ($n <= 1);
return fibonacci_memoize($n - 1) + fibonacci_memoize($n - 2);
}
fibonacci_neopt(25);
fibonacci_opt(25);
fibonacci_memoize(25);
Každý z nich jsme použili k získání 26. čísla z Fibonacciho posloupnosti. Co bude trvat nejděle a jak dlouho? Zkusme se na to podívat pomocí profileru a jen pozorujme, co všechno se dozvíme.
Použití profileru
Předpokládejme, že předchozí kód máme uložen v souboru fib.pl. Použití je velmi jednoduché. Celá teorie tohoto dílu se nyní vejde do dvou příkazů.
Pomocí toho prvního spustíme program a změříme časy pro všechno, co lze.
$ perl -d:NYTProf fib.pl
Vznikne nám soubor nytprof.out, kde jsou surová data. Rádi bychom je viděli v nějaké čitelné podobě, takže je zkonvertujeme do html:
$ nytprofhtml
To je vše, data jsou připravena.
Výsledky analýzy
Nyní máme v adresáři nytprof řadu html souborů, ze kterých zkusme spustit v prohlížeči index.html.
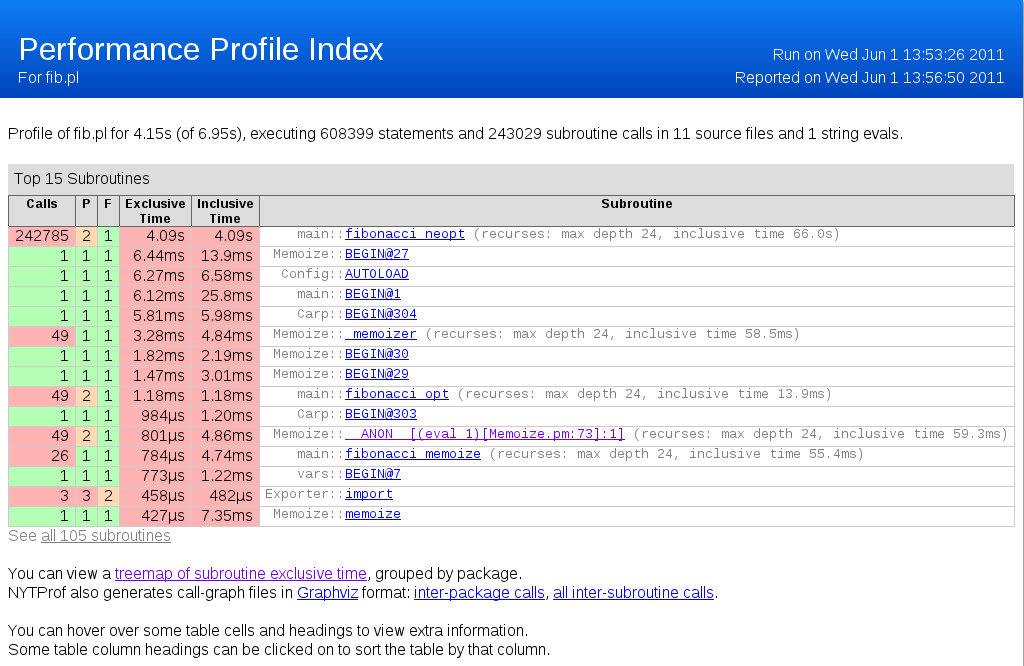
Horní část úvodní stránky
Co můžeme vidět? První řádek nám dá velmi zajímavou informaci:
Profile of fib.pl for 4.15s (of 6.95s), executing 608399 statements and
243029 subroutine calls in 11 source files and 1 string evals.
Profiler počítá s veškerým kódem, který proběhl - tedy i s importovanými moduly. Dva časy ("exclusive time" a "inclusive time") jsou uváděny všude. První znamená čas, který jsme strávili právě uvnitř aktuálního podprogramu; pokud z něj voláme jiné podprogramy, tento čas se nepočítá. Druhý čas pak započítává i čas strávený ve volaných podprogramech. "Inclusive time" je tedy vždy větší nebo roven "exclusive time" a součet všech "inclusive time" může výrazně převyšovat dobu běhu programu, protože se některé úseky započítavají vícekrát.
Dalším údajem zde jsou sloupce se záhlavím P resp. F. Sloupec P udává počet míst, odkud je daný podprogram volán. F je počet souborů, odkud je podprogram volán (tedy P je vždy větší nebo rovno než F).
Analýza podprogramů
Nyní se podívejme na první tabulku. V ní jsou seřazené všechny použité funkce a podprogramy podle toho, kolik času s nimi procesor strávil.
Všimněme si prvního řádku - naše neoptimalizovaná verze pro výpočet 26. čísla Fibonacciho posloupnosti byla volána 240 000 × jen kvůli výpočtu jednoho jednoduchého čísla. Tato volání zabrala astronomických 4,09 sekundy.
Naše optimalizovaná verze volala sama sebe jen 49× a zabrala 1,18 milisekund, tedy odhadem 4000× méně. Navíc další volání by byla se zapamatovanými daty ještě podstatně rychlejší.
Memoizovaná verze byla zdánlivě ještě dvakrát rychlejší, avšak ve výsledku není započítána režie okolo (jen samotné volání memoize zabralo skoro půl milisekundy).
Všimněme si obarvení na škále mezi zelenou a červenou. Čím je dané číslo červenější, tím větší je náročnost toho, k čemu je přiřazeno. Ovšem implicitní nastavení není příliš citlivé a tak se většinou stává, že červené je skoro všechno. Je to však dobré minimálně k jedné věci: tomu, co není nejčervenější, se nemá smysl při optimalizaci věnovat.
Barevně jsou ve výsledku profileru označeny také místa, kde používáme proměnné $&, $‘, $’, které výrazně zpomalují regulární výrazy.
Zkusme nyní kliknout na některý z našich podprogramů. U toho neoptimalizovaného můžeme krásně vidět, jak mnohokrát se který výraz vyhodnocuje.

Neoptimalizovaná verze
U optimalizované verze můžeme vidět markantní rozdíl.

Optimalizovaná verze
Stejně tak u memoizované verze.

Memoizovaná verze
Doplňme, že nahoře lze přepínat mezi block view, line view a sub view - podle toho, tak podrobně se mají statistiky ukazovat.
Další zajímavou věci je Subroutine Exclusive Time Treemap. Výsledkem je odbélníkový graf, který se sestává z menších obdélníků reprezentujících jednotlivé podprogramy. Obsah obdélníku jsou úměrné času, který program v daném podprogramu strávil.
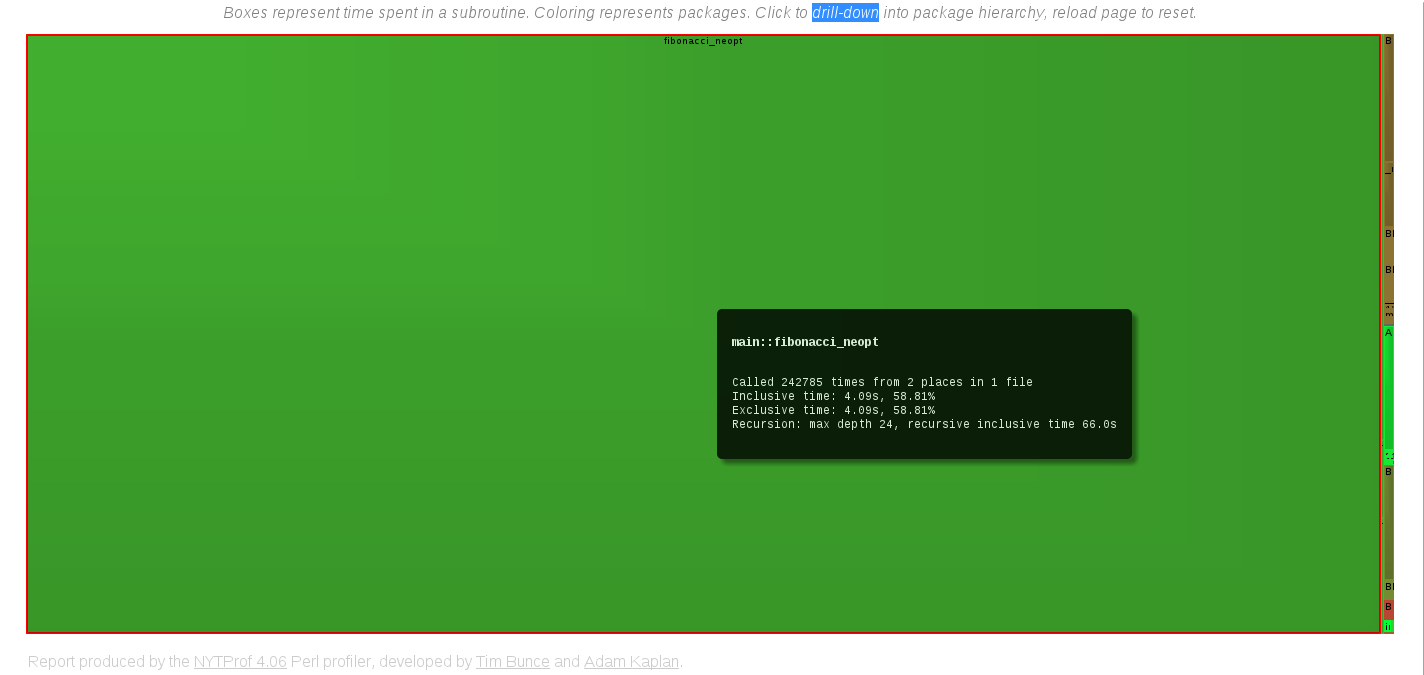
Sub Treemap
Treemap z takto malého programu, kde má navíc jeden podprogram tak obrovskou majoritu, vůbec nevypadá jako treemap. Každý si však může zkusit profilovat jakýkoliv jiný program a pak může výsledek vypadat např. jako ukázka na blogu Tima Bunceho.
Analýza souborů
Podívejme se nyní na spodní tabulku úvodní stránky.

Dolní část úvodní stránky
Zde vidíme, z kterých všech souborů jsme používali kód. To je samo o sobě zajímavé. Ještě zajímavější však je pohled na to, kolik výrazů bylo v daném souboru vyhodnoceno a kolik času to celkem zabralo včetně nějaké základní statistické analýzy.
Kliknutím na line, block nebo sub opět dostaneme rozepsání zdrojového kódu s podrobnějšími výsledky.
Jak optimalizovat
Optimalizace kódu bývá obvykle velmi nepříjemná. Je třeba postupovat systematicky od malých úprav a algoritmy pokud možno neměnit, protože to se může snadno zvrtnout v nekonečnou bezvýslednou práci.
Uveďme si pár triků, které ale snadno udělat lze a mnohdy mohou k požadovanému výsledku stačit. Když stačit nebudou, je to špatné a asi nezbude než se zamyslet nad algoritmem.
- Volání return bychom měli vždy provést ihned, jakmile známe výsledek. Stejně tak lze odfiltrovat některé triviální případy. Dostaneme takovou konstelaci parametrů, že lze použít snažší postup, přeskočit část výpočtu, hned vrátit výsledek apod.? Pak toho využijme.
- Opakované volání stejných metod nad stejnými daty je zbytečné - v případě, že je to v kódu "blízko", je nejlepší to řešit uložením do dočasné proměnné; nastává-li to dokonce globálně, pak zvažme použití memoizace.
- Cokoliv, co může být mimo cyklus, umístíme mimo něj.
- Jakmile lze z cyklu vyskočit (již máme vše potřebné), uděláme to.
- Cokoliv, co může být v podmínce (u které není složité ověřování testu), umístíme do ní.
- Občas existují rychlejší externí moduly, které se dají použít (ať už místo nějakých jiných externích modulů nebo místo vlastního kódu).
- Místo cyklů, jejichž hlavní náplní je volání nějaké metody, lze napsat metodu, která zpracovává seznam parametrů. Tato metoda bývá často rychlejší.
Zjišťování kvality testů
Pomocí profileru Devel::Cover lze získávat informaci o tom, kolik procent kódu bylo použito. To se hodí zejména při testování, nakolik test skripty pokrývají modul. Jako výsledek získáme informaci o tom, jaký kód jsme otestovali a jaký ještě ne.
Další informace
Stojí za to zhlédnout prezentaci o Devel::NYTProf z OSCON 2010. Je zde interaktivně vysvětleno, jak profiling využívat.
Předchozí Celou kategorii (seriál) Další
Perl (2) - Úvod do syntaxe
Perl (3) - Proměnné
Perl (4) - Čísla a řetězce
Perl (5) - Podmínky
Perl (6) - Pravdivostní výrazy
Perl (7) - Vstup poprvé
Perl (8) - Některé základní vestavěné funkce
Perl (9) - Cykly
Perl (10) - Další řídící struktury
Perl (11) - Pole - úvod
Perl (12) - Pole - základní operace
Perl (13) - Hashe
Perl (14) - Další nástroje pro seznamy
Perl (15) - Výchozí proměnná, heredoc, symbolické odkazy
Perl (16) - Regulární výrazy - začínáme
Perl (17) - Regulární výrazy - kotvy
Perl (18) - Regulární výrazy - množiny znaků
Perl (19) - Regulární výrazy - opakování a kvantifikátory
Perl (20) - Regulární výrazy - magické závorky
Perl (21) - Regulární výrazy - nahrazování
Perl (22) - Regulární výrazy - přepínače
Perl (23) - Regulární výrazy - rozšířené vzory
Perl (24) - Regulární výrazy - příklady
Perl (25) - Regulární výrazy - závěr
Perl (26) - Podprogramy
Perl (27) - Prototypy
Perl (28) - Rozsahy platnosti proměnných
Perl (29) - Úvod k práci se soubory
Perl (30) - Práce se soubory
Perl (31) - Testování souborů
Perl (32) - Jiné typy souborů
Perl (33) - Formátování výstupu - printf
Perl (34) - Formátování výstupu - formáty
Perl (35) - Vestavěný debugger
Perl (36) - Grafické debuggery
Perl (37) - Začínáme s moduly
Perl (38) - Rozhraní modulu
Perl (39) - Pragma
Perl (40) - Dodatky k modulům
Perl (41) - CPAN
Perl (42) - Argumenty příkazového řádku
Perl (43) - Přepínače
Perl (44) - Dlouhé přepínače
Perl (45) - Odkazy
Perl (46) - Užití odkazů a anonymní data
Perl (47) - Složitější datové struktury
Perl (48) - Libovolně složité datové struktury
Perl (49) - Tabulky symbolů a typegloby
Perl (50) - Uzávěry a iterátory
Perl (51) - Signály
Perl (52) - Externí příkazy
Perl (53) - Režim nakažení
Perl (54) - Fork
Perl (55) - Eval
Perl (56) - Volby příkazu perl
Perl (57) - Jednořádkové skripty
Perl (58) - OOP - úvod
Perl (59) - OOP - typické použití
Perl (60) - OOP - dědičnost
Perl (61) - OOP - přínos a užití dědičnosti
Perl (62) - OOP - přetěžování
Perl (63) - OOP - závěr
Perl (64) - Projekt - čtečka sportovních výsledků
Perl (65) - Projekt - získání dat
Perl (66) - Projekt - výběr zápasů a podrobnosti
Perl (67) - Projekt - dokončujeme modul
Perl (68) - Projekt - zobrazení zápasů
Perl (69) - Projekt - online přenos
Perl (70) - Plain Old Documentation
Perl (71) - Navazování proměnných
Perl (72) - Navazování složitějších datových typů
Perl (73) - DBM
Perl (74) - Sockety
Perl (75) - Obsluha více klientů
Perl (76) - Síťová hra v kostky
Perl (77) - Služby internetu
Perl (78) - Databáze - úvod
Perl (79) - Databáze - manipulace s daty
Perl (80) - Databáze - závěrečné poznámky
Perl (81) - CGI - příprava webového serveru
Perl (82) - CGI - první skripty
Perl (83) - CGI - získávání dat od uživatele
Perl (84) - CGI - usnadnění tvorby skriptů pomocí modulu CGI
Perl (85) - CGI - generování dokumentu modulem CGI
Perl (86) - CGI - cookies
Perl (87) - CGI - příklad aplikace
Perl (88) - CGI - závěr
Perl (89) - Mason - snadné psaní webů
Perl (90) - Mason - speciální bloky
Perl (91) - Mason - handlery
Perl (92) - Mason - závěr
Perl (93) - Catalyst - MVC framework pro Perl
Perl (94) - Catalyst - základy pro psaní aplikace
Perl (95) - Catalyst - šablony
Perl (96) - Catalyst - spolupráce s databází
Perl (97) - Curses - tvorba textových uživatelských rozhraní
Perl (98) - Curses - pozicování a okna
Perl (99) - Curses - měření rychlosti psaní
Perl (100) - Curses - použití hotových widgetů
Perl (101) - Curses - jednoduchý textový editor
Perl (102) - Rozšiřování Perlu pomocí XS
Perl (103) - Rozšiřování Perlu pomocí SWIG
Perl (104) - Testování rychlosti
Perl (105) - Testování programových jednotek
Perl (106) - Debugování pomocí komentářů
Perl (107) - Moose - moderní objektový systém
Perl (108) - Moose - základní vlastnosti
Perl (109) - Moose - role
Perl (110) - Moose - meta API
Perl (111) - Pokročilá práce se seznamy
Perl (112) - Práce s PDF
Perl (113) - Práce s archivy
Perl (114) - Tk - úvod
Perl (115) - Tk - umísťování widgetů
Perl (116) - Tk - základní widgety
Perl (117) - Tk - některé pokročilejší widgety
Perl (118) - Tk - čas a události
Perl (119) - Tk - CD man
Perl (120) - Wx - základní práce s widgety
Perl (121) - Wx - události
Perl (122) - Gtk2 - úvod
Perl (123) - Gtk2 - základní práce s obrázky
Perl (124) - Gtk2 - události a čas
Perl (125) - Gtk2 - vlastní widgety
Perl (126) - Gtk2 - textové okno a práce s pozicemi
Perl (127) - Gtk2 - hierarchické seznamy
Perl (128) - Gtk2 - dialogy
Perl (129) - Gtk2 - skládání widgetů
Perl (130) - Gtk2 - menu a toolbary
Perl (131) - Gtk2 - transparentní okna, tray ikona, výběr souborů
Perl (132) - Gtk2 - drag&drop, druid
Perl (133) - Gtk2 - úpravy vzhledu aplikací pomocí rc
Perl (134) - Gtk2 - Glade Interface Designer
Perl (135) - XML - čtení a zápis
Perl (136) - XML - DOM a SAX přístupy
Perl (137) - Vlákna
Perl (138) - Memoizace - cachování podprogramů
Perl (140) - Profilling - píšeme si vlastní profiler / debugger
Perl (141) - Formátování kódu, deparsování, perltidy
Perl (142) - Způsoby konfigurování
Perl (143) - Struktura datových typů, správa paměti
Perl (144) - POE - událostmi řízené programování
Perl (145) - POE - aplikace typu klient-server
Perl (146) - Perl 6 - jazyk budoucnosti
Perl (147) - Perl 6 - regulární výrazy, nové operátory
Perl (148) - Perl Culture
Perl (149) - Závěr
Pozvánka na Český Perl Workshop
Perl 5.22.0 a vše okolo
Perl 5.24.0 a vše okolo
Předchozí Celou kategorii (seriál) Další
|
Nejsou žádné diskuzní příspěvky u dané položky. Příspívat do diskuze mohou pouze registrovaní uživatelé. | |
28.11.2018 23:56 /František Kučera
Prosincový sraz spolku OpenAlt se koná ve středu 5.12.2018 od 16:00 na adrese Zikova 1903/4, Praha 6. Tentokrát navštívíme organizaci CESNET. Na programu jsou dvě přednášky: Distribuované úložiště Ceph (Michal Strnad) a Plně šifrovaný disk na moderním systému (Ondřej Caletka). Následně se přesuneme do některé z nedalekých restaurací, kde budeme pokračovat v diskusi.
Komentářů: 1
12.11.2018 21:28 /Redakce Linuxsoft.cz
22. listopadu 2018 se koná v Praze na Karlově náměstí již pátý ročník konference s tématem Datová centra pro business, která nabídne odpovědi na aktuální a často řešené otázky: Jaké jsou aktuální trendy v oblasti datových center a jak je optimálně využít pro vlastní prospěch? Jak si zajistit odpovídající služby datových center? Podle jakých kritérií vybírat dodavatele služeb? Jak volit vhodné součásti infrastruktury při budování či rozšiřování vlastního datového centra? Jak efektivně datové centrum spravovat? Jak co nejlépe eliminovat možná rizika? apod. Příznivci LinuxSoftu mohou při registraci uplatnit kód LIN350, který jim přinese zvýhodněné vstupné s 50% slevou.
Přidat komentář
6.11.2018 2:04 /František Kučera
Říjnový pražský sraz spolku OpenAlt se koná v listopadu – již tento čtvrtek – 8. 11. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma umění a technologie, IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
4.10.2018 21:30 /Ondřej Čečák
LinuxDays 2018 již tento víkend, registrace je otevřená.
Přidat komentář
18.9.2018 23:30 /František Kučera
Zářijový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 20. 9. 2018 od 18:00 v Radegastovně Perón (Stroupežnického 20, Praha 5). Tentokrát bez oficiální přednášky, ale zato s dobrým jídlem a pivem – volná diskuse na téma IoT, CNC, svobodný software, hardware a další hračky.
Přidat komentář
9.9.2018 14:15 /Redakce Linuxsoft.cz
20.9.2018 proběhne v pražském Kongresovém centru Vavruška konference Mobilní řešení pro business.
Návštěvníci si vyslechnou mimo jiné přednášky na témata: Nejdůležitější aktuální trendy v oblasti mobilních technologií, správa a zabezpečení mobilních zařízení ve firmách, jak mobilně přistupovat k informačnímu systému firmy, kdy se vyplatí používat odolná mobilní zařízení nebo jak zabezpečit mobilní komunikaci.
Přidat komentář
12.8.2018 16:58 /František Kučera
Srpnový pražský sraz spolku OpenAlt se koná ve čtvrtek – 16. 8. 2018 od 19:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát jsou tématem srazu databáze prezentaci svého projektu si pro nás připravil Standa Dzik. Dále bude prostor, abychom probrali nápady na využití IoT a sítě The Things Network, případně další témata.
Přidat komentář
16.7.2018 1:05 /František Kučera
Červencový pražský sraz spolku OpenAlt se koná již tento čtvrtek – 19. 7. 2018 od 18:00 v Kavárně Ideál (Sázavská 30, Praha), kde máme rezervovaný salonek. Tentokrát bude přednáška na téma: automatizační nástroj Ansible, kterou si připravil Martin Vicián.
Přidat komentář
31.7.2023 14:13 /
Linda Graham
iPhone Services
30.11.2022 9:32 /
Kyle McDermott
Hosting download unavailable
13.12.2018 10:57 /
Jan Mareš
Re: zavináč
2.12.2018 23:56 /
František Kučera
Sraz
5.10.2018 17:12 /
Jakub Kuljovsky
Re: Jaký kurz a software by jste doporučili pro začínajcího kodéra?